企业AI解决方案马来西亚
让 AI 投入工作的三种方式——选择您的路径
从代理 AI 助理到私人 LLM 部署 - 我们构建、部署和支持企业 AI 解决方案,这些解决方案改变了马来西亚企业的运营方式。
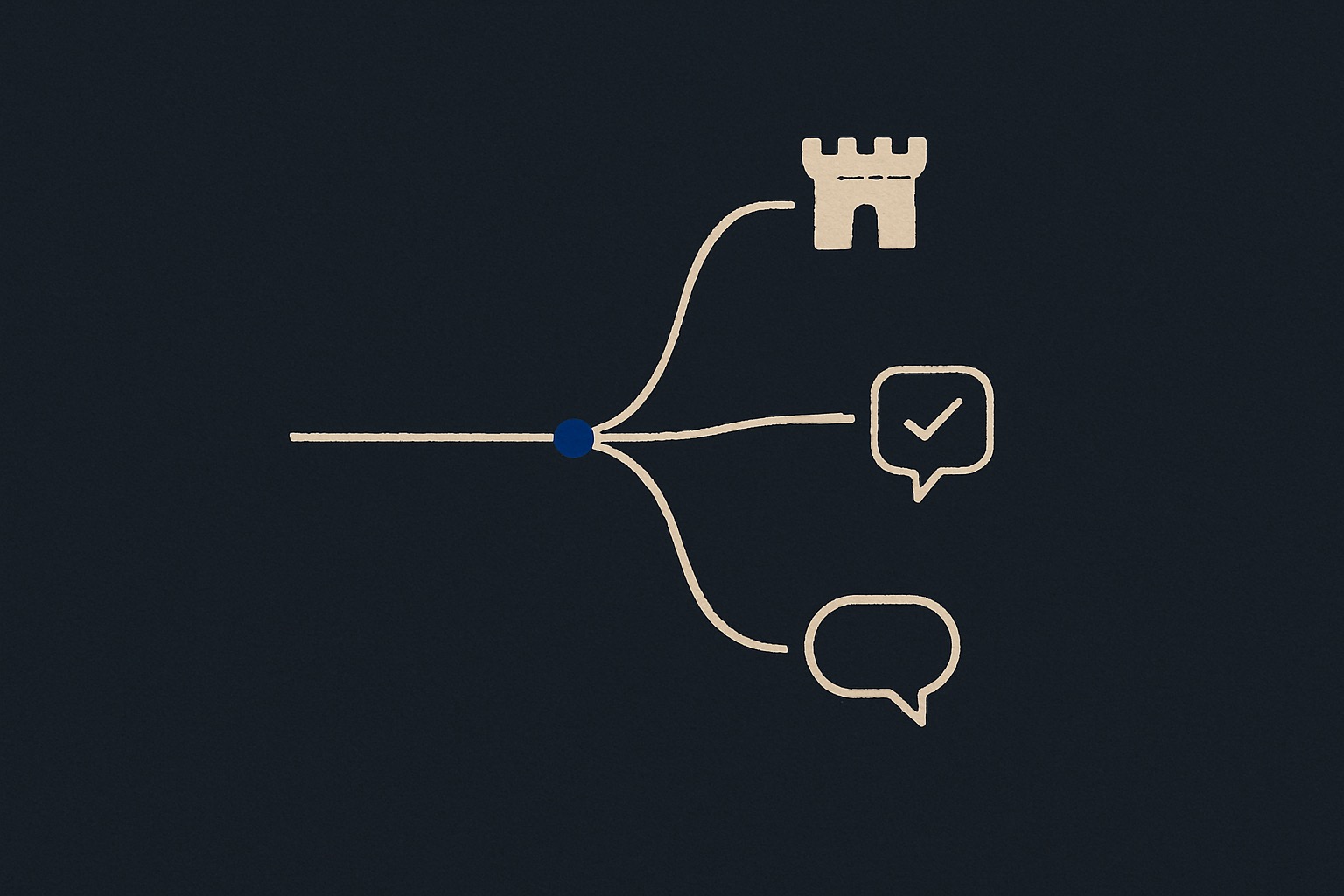
代理运行时
我们的智能体如何真正完成工作。规划。执行。验证。
我们交付的每个 AI 代理都运行同一套严谨的循环——自主运行绝不意味着失去对质量、安全或合规的掌控。
规划
智能体把您的目标分解为具体步骤——检索知识、选择工具,并在任何操作运行之前编排好工作顺序。
- 目标分解
- 工具选择
- 知识检索
行动
它针对您的真实系统执行每一步——调用 API、更新记录、起草文档,并自主推进工作。
- API 与系统调用
- 文档起草
- 工作流执行
校验
每个结果都会按安全护栏和验收标准进行检查。任何未通过的环节都会回到规划阶段,直到任务完成。
- 护栏检查
- 结果验证
- 自我纠正循环
验证结果反馈到规划环节——循环持续运行,直至通过验收标准。
开放模型
自带模型。数据留在您手中。
通过 vLLM 部署在您自己的 GPU 上——没有按 token 计费的 API 费用,也没有供应商锁定。
ThinkStation PX SFF
AI 工作站合作伙伴
紧凑型 AI 工作站,配备 NVIDIA RTX 专业 GPU。非常适合本地 LLM 推理和开发。
- 多达 2 个 NVIDIA RTX 6000 Ada
- 英特尔至强 W 处理器
- 小外形设计
- 企业可靠性
Ascent GX10
AI 工作站合作伙伴
针对大型语言模型工作负载进行优化的高性能 AI 服务器。适用于企业部署的可扩展 GPU 计算。
- 多 GPU 配置
- 针对 LLM 推理进行优化
- 企业级冷却
- 24/7 运营认证
全栈AI部署 — 我们负责软件、硬件采购、安装与持续支持。一个合作伙伴,覆盖您完整的 AI 基础设施。
特色产品和服务
AI 产品与 OpenClaw 部署服务
生产就绪的 AI 助手以及专业的 OpenClaw 设置和托管服务。选择本地 SaaS,或者让我们管理您的 AI 基础设施。

AI 服务
满足各种需求的 AI 解决方案
从对话式 AI 到企业自动化 - 我们拥有构建、部署和支持您的 AI 计划的专业知识。
私有 LLM 部署
使用 vLLM 在您自己的基础设施上部署开源 LLM。完全数据隐私,无需外部 API 调用。您的数据归您所有。
为什么选择我们
马来西亚的AI 集成专家
我们将深厚的 AI 专业知识与本地业务相结合,提供适合马来西亚企业的企业解决方案。
100% 数据隐私
您的数据永远不会离开您的基础设施。我们在您的服务器上部署 AI 并提供气隙选项。无需云依赖。
生产就绪 vLLM
使用 vLLM 框架进行企业级推理。高吞吐量、低延迟,并针对标准 GPU 硬件上的生产工作负载进行了优化。
全部开源 LLM
支持 Llama、Qwen、Mistral、DeepSeek 等。选择最适合您的用例的模型,而无需受供应商锁定。
马来西亚本地团队
没有海外支持。我们的 AI 工程师常驻 马来西亚,提供响应支持、现场部署和持续优化。
端到端交付
从需求到生产部署。我们负责基础设施、模型选择、微调、集成和持续维护。
透明定价
没有隐藏的 API 成本或每个代币费用。通过可选支持合同进行一次性部署。您拥有基础设施。
行业
覆盖各行各业的 AI 解决方案
我们已在不同行业部署了 AI 解决方案,每个行业都有独特的要求和合规性需求。
金融与银行
制造业
零售与电子商务
法律与专业
医疗保健
政府及官联公司
教育
物流与供应链
常问问题
常见问题
有关我们的 AI 解决方案和部署方法的常见问题。
OpenClaw 是一个流行的开源、自托管 AI 代理平台,可让您在自己的基础设施上运行自主 AI 代理。我们提供专业的 OpenClaw 设置、部署和托管服务 - 处理基础设施配置、安全强化和持续维护,以便您可以利用 OpenClaw 强大的 AI 代理功能,而无需承担运营负担。
虽然 OpenClaw 是开源且免费使用的,但在生产中运行它需要基础设施、安全性和 AI 操作方面的专业知识。我们的 OpenClaw 托管服务可处理服务器配置、安全修补、性能调整和 24/7 监控 - 让您的团队专注于构建 AI 工作流程,而不是管理基础设施。我们提供有保证的 SLA 的企业支持。
我们专注于本地部署,您的数据永远不会离开您的基础设施。使用 vLLM、OpenClaw 和开源模型,我们完全在您的网络内部署 AI — 无需外部 API 调用,无需云依赖。 OpenClaw 的自托管架构意味着您的 AI 代理在您的服务器上运行,具有完全的数据主权。
我们支持所有主要开源 LLM,包括 Llama 3.1/3.2、Qwen 2.5、Mistral、DeepSeek 等。我们的 vLLM 基础设施可以运行任何 Hugging Face 兼容模型。 OpenClaw 可以配置为这些型号中的任何一个。我们帮助您根据您的使用案例、语言要求(包括印尼语 马来西亚 和中文)和硬件限制选择最佳模型。
基本的 EzyChat 部署可在 1-2 周内完成。 OpenClaw 设置和部署通常需要 2-3 周,包括基础设施配置和安全强化。定制代理 AI 开发需要 4-8 周,具体取决于复杂程度。具有 RAG 系统的完整私有 LLM 基础设施通常需要 6-12 周。
我们提供灵活的支持包,包括系统监控、模型更新、性能优化和故障排除。对于 OpenClaw 部署,我们的托管服务包括 24/7 监控、自动更新、主动维护和保证响应时间的优先支持 - 所有这些均由我们专门的 AI 运营团队处理。